AI For Humanity
Lecture 2 - Tree-based methods and Neural Networks
2025-09-10
Setup
Consider a dataset with outcomes belonging to \(3\) classes…

Setup
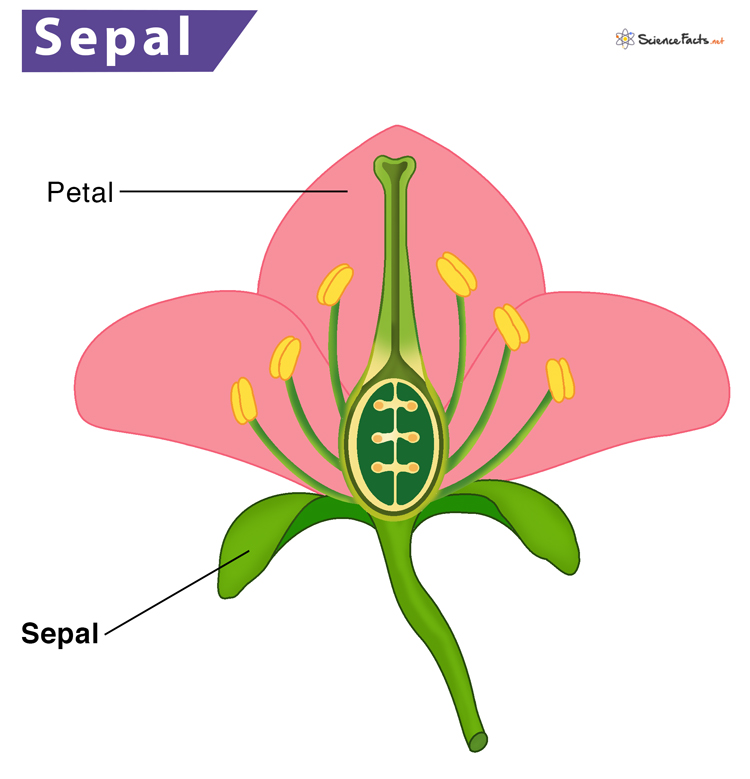
The Iris dataset (Fisher, 1936)

Setup
yields:
:Number of Instances: 150 (50 in each of three classes)
:Number of Attributes: 4 numeric, predictive attributes and the class
:Attribute Information:
- sepal length in cm
- sepal width in cm
- petal length in cm
- petal width in cm
- class:
- Iris-Setosa
- Iris-Versicolour
- Iris-Virginica
============== ==== ==== ======= ===== ====================
Min Max Mean SD Class Correlation
============== ==== ==== ======= ===== ====================
sepal length: 4.3 7.9 5.84 0.83 0.7826
sepal width: 2.0 4.4 3.05 0.43 -0.4194
petal length: 1.0 6.9 3.76 1.76 0.9490 (high!)
petal width: 0.1 2.5 1.20 0.76 0.9565 (high!)
============== ==== ==== ======= ===== ====================- Goal: classify iris flowers to the three categories
- Approach: we’ll use a Decision Tree as our classifier


{kind=link}
{kind=link}
All 2-combinations of features
Could we carve out the feature space…?

Asking questions to the data

Inspecting the Tree
- Question: consider \(X_{i} = (6.1, 2.6, 5.6, 1.4)^{T}\); what is the predicted label \(\hat{Y}_{i}?\)
- Order of \(X\) variables: (sepal length, sepal width, petal length, petal width)
Inspecting the Tree
Question: consider the nonterminal node with \(N(t) = 84\).
- Compute the vector of estimated conditional probabilities: \[ (p(1 \mid t), p(2 \mid t), p(3 \mid t))^{T} \] using the expression on the previous slides and the counts in the tree
- Compute \(p_{L}\) and \(p_{R}\) relative to the same node \(t\)
Split \(s\)

Illustration of split from (Breiman, 1984)
Impurity functions

In the two-class case; image from ESLII.
Computing impurity
- Question: compute \(\Delta i(s, t)\) for the nonterminal node from before with \(N(t) = 84\); you can use the function below and \(p_{L}\) and \(p_{R}\) from before.

Setup
- The MNIST dataset consists of 70,000 images of handwritten digits (0–9), each a 28 × 28 pixel grayscale image
- 50,000 training images; 10,000 validation images; 10,000 test images

- We reshape the pixel matrices into \(28 \cdot 28 = 784\)-dimensional vectors, \(x_{i} \in \mathbb{R}^{784 \times 1}\); also, we divide them by \(255\)
- We one-hot encode the labels \(y_{i} \in \{0, 1\}^{10 \times 1}\) (with a \(1\) at the index corresponding to the true label and \(0\) elsewhere)
- Our goal is to estimate a neural network (think of it as a complex non-linear statistical model) to correctly predict the class labels
A Neural Network

Neural Network Weights

Backpropagation - Equations
